
Metadata. Data about Data.
The more metadata you have, the more insights you’ll derive without actually looking at the raw data. And the great thing about metadata is its “tiny data” in comparison to the data it’s describing – even if you compile a lot of it.
That’s why metadata is the main resource harvested by a lot of technologies that power modern life.
Search Engine Optimization (SEO), for example, is primarily about marking up your web content with schema.org metadata, so Search Engines can infer, rank and classify what your website is about without fully ingesting its content.
Large Language Models (LLMs) also work on a form of “derived metadata” – weights, vectors describing the strength of each connection in a neural network as it ingests massive amounts of training data.
For both SEO and LLMs, there are a multitude of tools and techniques to compile this metadata. And once compiled, they both enable impressive – some may say “magical” applications – Search Engines and Chatbots in particular.
The State of the Art – Card Catalog style

Metadata catalogs can also have this “magical” quality IF it’s populated, curated and maintained properly, enabling organizations who invest in it to have an enterprise-wide view of their Strategic Data Assets regardless of its source and underlying technology.
However, as we pointed out in the previous blog post, compiling this metadata for Data Catalogs has largely been a manual, error-prone process that has led to less dynamic, less comprehensive Data Portals.
A process not dissimilar to compiling an old-fashioned Library Card Catalog.
Though several installations we’ve been involved with have impressive data ingestion pipelines using the latest machine learning algorithms & services – they only solved their specific data onboarding and metadata inferencing requirements. For the most part, the pipelines were bespoke, non-reusable and were only made possible because they had ready access to data engineering teams and domain experts inside the organization.
With recent initiatives like Findable, Accessible, Interoperable & Reusable (FAIR) data; the just released v3 of the Data Catalog Vocabulary (DCAT 3) standard; and ongoing efforts in both Europe (DCAT-AP 3) and the US (DCAT-US 3) to create specific DCAT 3 profiles that implement these FAIR principles in wide-ranging data infrastructure programs – metadata cataloging requirements will even become even more demanding.
But it’s worth it. In this Information Age, as our data assets double every two years, a comprehensive metadata catalog will become an essential part of any organization’s data management strategy. And the way to do it is not with a proprietary, bespoke implementation, the only way is with an open standard – DCAT.
DCAT-US 3.0 in particular has big ambitions:
DCAT-US 3.0 introduces a highly refined, interoperable, and future-proof framework for describing and validating dataset metadata. In essence, it is not just a specification but an advanced stride towards achieving a data-centric landscape where precise metadata description empowers the efficient flow of information while laying the groundwork for sustained innovation. (highlight ours)
https://doi-do.github.io/dcat-us/#abstract
Once approved and implemented, the update will improve the FAIRness, or Findability, Accessibility, Interoperability, and Reusability of all types of federal data. DCAT-US v3 will provide a single metadata standard able to support most requirements for documentation of business, technical, statistical, and geospatial data consistently. (highlight ours)
https://github.com/DOI-DO/dcat-us/#readme
That’s why it’s imperative that we reinvent the data/metadata ingestion process. For these standards demand even more detailed metadata, and if we stick with the current metadata ingestion/curation regimen, Data Publishers will be even less likely to tend their Data Catalogs.
We need something that is not only Super Easy and Worthwhile as we mentioned in the last blog post, we need to Democratize it as well, so it’s widely available even to installations who do not have ready access to Data Engineering resources.
Reinventing the Data Catalog through User Research
Fortunately, shortly after the failed hedge fund pilot in the previous post, we got involved in what we at first thought was a typical CKAN implementation co-creating Texas’ Water Data Hub.
Soon after the kickoff however, we found out that it was not your typical CKAN implementation – for they have done extensive, years-long User Research and an exhaustive survey of available data portal platforms beforehand.
Before even one line of code was written, the Texas team went through an extensive Discover/Define/Develop process, and by the time we got involved to Deliver and co-create the state’s Water Data Hub, they already had detailed wireframes and designs that were the result of this extensive research.
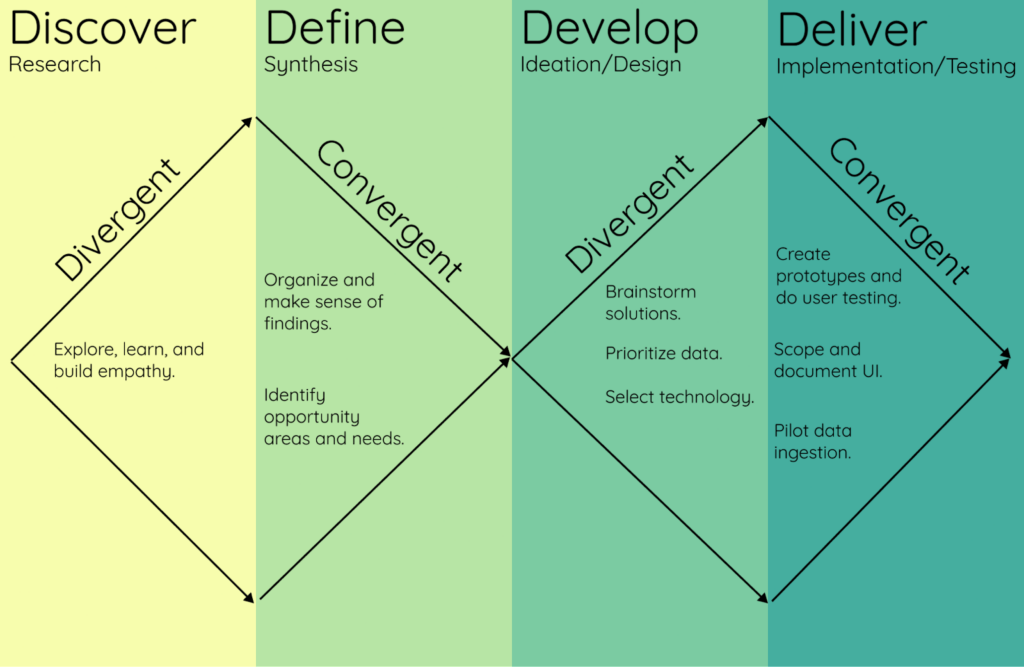
And for us, what really set their project apart was that they “asked subject matter experts representing 10 open data platforms about data sharing, governance, and hubs. Our goal was to learn from those who have already tread this path; to understand pitfalls to look out for and identify opportunities to collaborate and build on existing work.”
And sure enough, they also found the existing data publishing process wanting, particularly for Data Publishers.
User Experience is Key – and Data Publisher UX comes first!

As we reviewed the wireframes with the Texas team – one thing that immediately caused concern was their desired data publishing workflow.
It was CKAN’s default workflow turned upside down!
Instead of filling out a long web form with dozens of metadata fields first and then uploading the data afterwards as is the default data ingestion workflow in CKAN, they envisioned starting with Data Resource Upload First (or “DRUF”, as we started calling it).
And the reason they’re uploading the Data First, is that they want CKAN to infer and prepopulate a lot of the metadata!
And it makes sense! Remember the untended Data Catalogs we wrote about? It was primarily because of the onerous data publishing process – the Data Publisher had to compile all the metadata beforehand and key it in manually.
By uploading and ingesting the Data First, CKAN can characterize and infer a lot of metadata in real-time and engage the Data Publisher in an iterative, interactive, just-in-time data-wrangling conversation.
Imagine a Data Publisher updating a dataset with this new CKAN DRUF workflow, uploading an Excel file with ~450,000 rows:
So the first upload found the Excel file was invalid. OK, that’s an easy fix as DRUF now tells me where the invalid record was – the 203,105th row is where it found missing data.
Reupload. Ooops, “Flow Stream instantaneous (cubic ft/sec)” is an invalid column name DRUF warns me, as parentheses and forward slash characters are not allowed in PostgreSQL; spaces are discouraged and folding column names to lowercase is a best practice. Thankfully, it automatically created a “safe” version (“flow_stream_instantaneous__cubic ft_sec_”) and saved the original column name in the Data Dictionary as the Display Label. It also warned me there are 23 duplicate rows. But that’s OK, DRUF automatically deduplicated it per my configuration.
Third time’s the charm… Dooh! The data did not validate properly per the JSON Schema constraints – the Reviewed field had an unexpected value – it only accepts “Approved”, “Rejected”, “Queued” and “Pending”, and fifteen rows had “In Progress”. There were also several rows dispersed throughout the file with empty mandatory fields per the validation report. No worries, the report had a reason column along with the row numbers of the four offending records.
Fourth time perhaps? This should be it… Yikes! It found several rows with Personally Identifiable Information (PII)! Thankfully, it quarantined the suspect rows, and even tells me what the problem was per row (several SSNs, three emails, five phone numbers, and some suspect credit card and bank account numbers) in a detailed PII report. Sometimes, those free text comment fields can bite you when over-earnest folks in the field enter TMI.
Fifth time… OK! The dataset now validates and is updated!
And look at this! It inferred several metadata fields automagically! It saw I had lat/long fields and automatically computed the spatial extent of the dataset. It also inferred that it’s a time-series dataset and it automatically created a unique index on the “Observation Date” column for faster time-series queries. Not only that, it prepopulated the “Date Range” metadata field and somehow inferred the periodicity of the dataset came in 5 minute intervals!
It did this by using the comprehensive summary statistics and frequency tables it compiled in less than four seconds in the background shortly after the Data Resource was first uploaded. It automatically recognized the lat/long fields based on their column names, data type (float), and their range (-90.0 to 90.0 for latitude, -180.0 t0 180.0 for longitude). It was able to infer the spatial extent based on the min/max values of the lat/long fields; it knew the “Observation Date” column was indeed a timestamp as it scanned all 450k rows and inferred the data type of each column; it knew it can be a unique index since the cardinality of the column was equal to the number of rows; and it inferred the Date Range of the observations based on the min/max values of “Observation Date”. It inferred the periodicity of the observations was 5 minutes when it ran an additional periodicity check after it determined “Observation Date” was indeed a timestamp column.
And based on the same summary statistics and the frequency tables it compiled behind the scenes as part of the DRUF process, it also created an extended Data Dictionary prepopulated with not just “Fieldname”, “Data Type” and “Display Label” (which it automatically sets to the original column name of columns with “unsafe” names), it also prepopulated the “Description” field with narrative description (e.g. “the Reviewed field describes the review status of the observation. The valid values are “Approved”, “Rejected”, “Queued” and “Pending”. There are 450,567 Approved, 10 Rejected, 97 Queued and 46 Pending in the dataset.”)
It also added the summary statistics and frequency tables as separate resources to the catalog entry of the dataset as “computed metadata.”
Finally, it auto-suggested several tags based on the column names and the dominant values in the frequency tables – this dataset is about “Water Quality” and based on the spatial extent, is for the “San Antonio river” in “Bexar” county.
Contrast this with CKAN’s existing data ingestion mechanisms (primarily – Datapusher and XLoader). Datapusher has type inferencing, but is excruciatingly slow and fails without any actionable feedback on what causes an error when it fails on the smallest Data Quality issue. XLoader (which we actually commissioned when we were at OpenGov because of our frustrations with Datapusher) is exponentially faster and more robust, but it does so by not bothering to infer data types at all and inserting everything as text. Regardless, both of them are batch-oriented and presume the metadata was prepared beforehand and the raw data was “perfect” as no Data Quality checks or metadata inferencing is done at all.
If we tried the same Excel file with Datapusher, it would have failed only after pushing the first 203,104 valid rows tens of minutes later without any actionable feedback on why it failed. With XLoader, the upload will also fail as it also does not do any Data Quality checks – but at least, you don’t have to wait as long. 🤷
With DRUF – Data Publishers are actively incentivized to refine the data using an interactive Wizard interface as part of an iterative data-wrangling process without the need for specialized tools and skills.
And since the main resource we organize in CKAN is metadata, by paying attention to the Data Publisher first, we naturally get more dynamic, relevant, up-to-date Data Catalogs. Data that is Useful, Usable and Used!
For it to work, however, you need to be able to ingest and characterize the data very Quickly – so you can iterate and interactively refine the data in near real-time.
Enter Quicksilver – qsv…
(To be continued)
